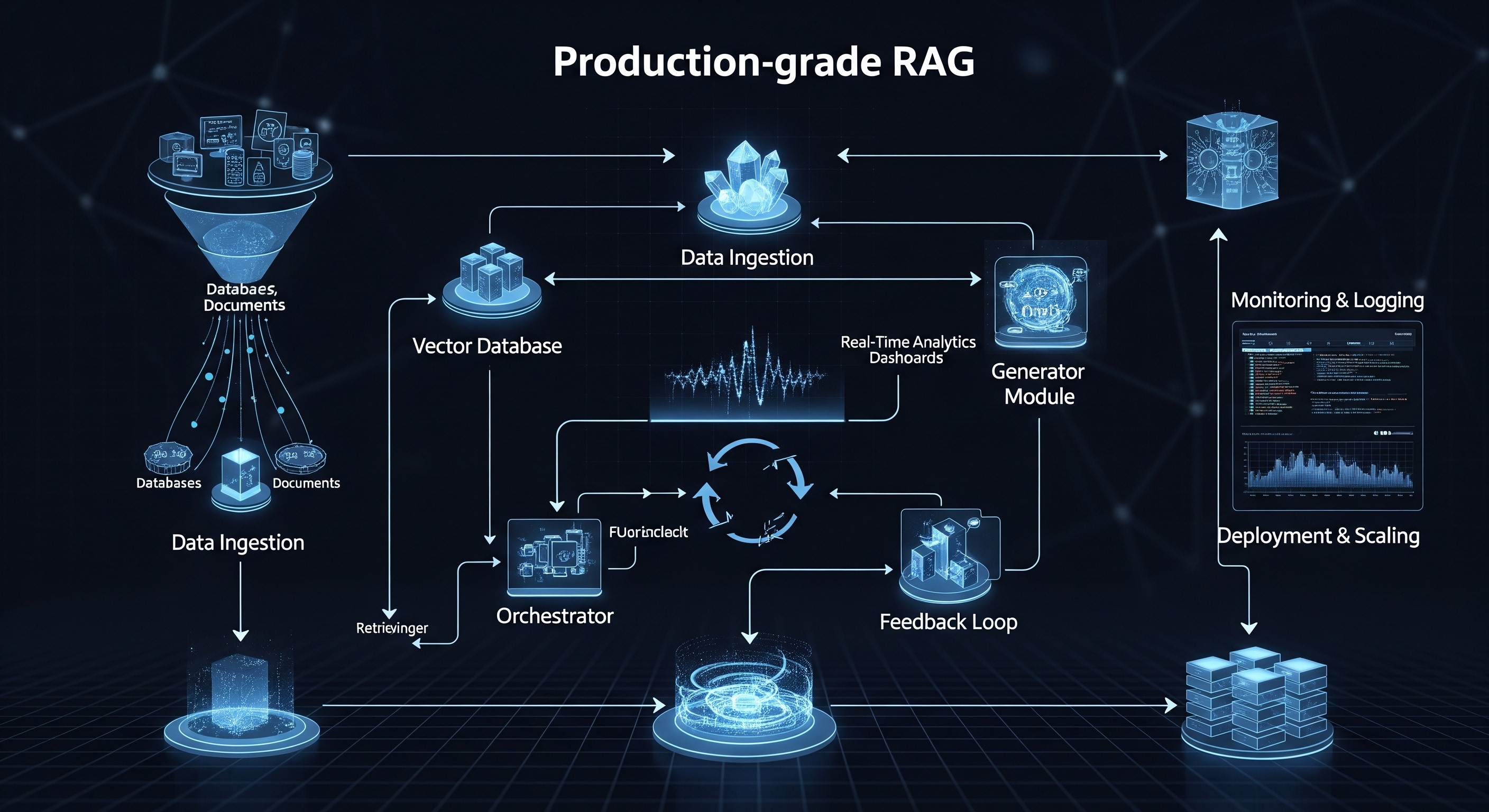
A Deep Dive into Our Privacy-First RAGaaS Pipeline
In the rapidly evolving landscape of artificial intelligence, Retrieval-Augmented Generation (RAG) has emerged as a game-changing technology. By grounding Large Language Models (LLMs) in your private, proprietary data, RAG unlocks unprecedented accuracy and relevance. But as we rush to harness this power, a critical question looms: how do we protect the very data that makes this technology so valuable? At RAGlink, we believe that trust isn't an afterthought; it's the foundation. That's why w…

CTO - Indie Hacker