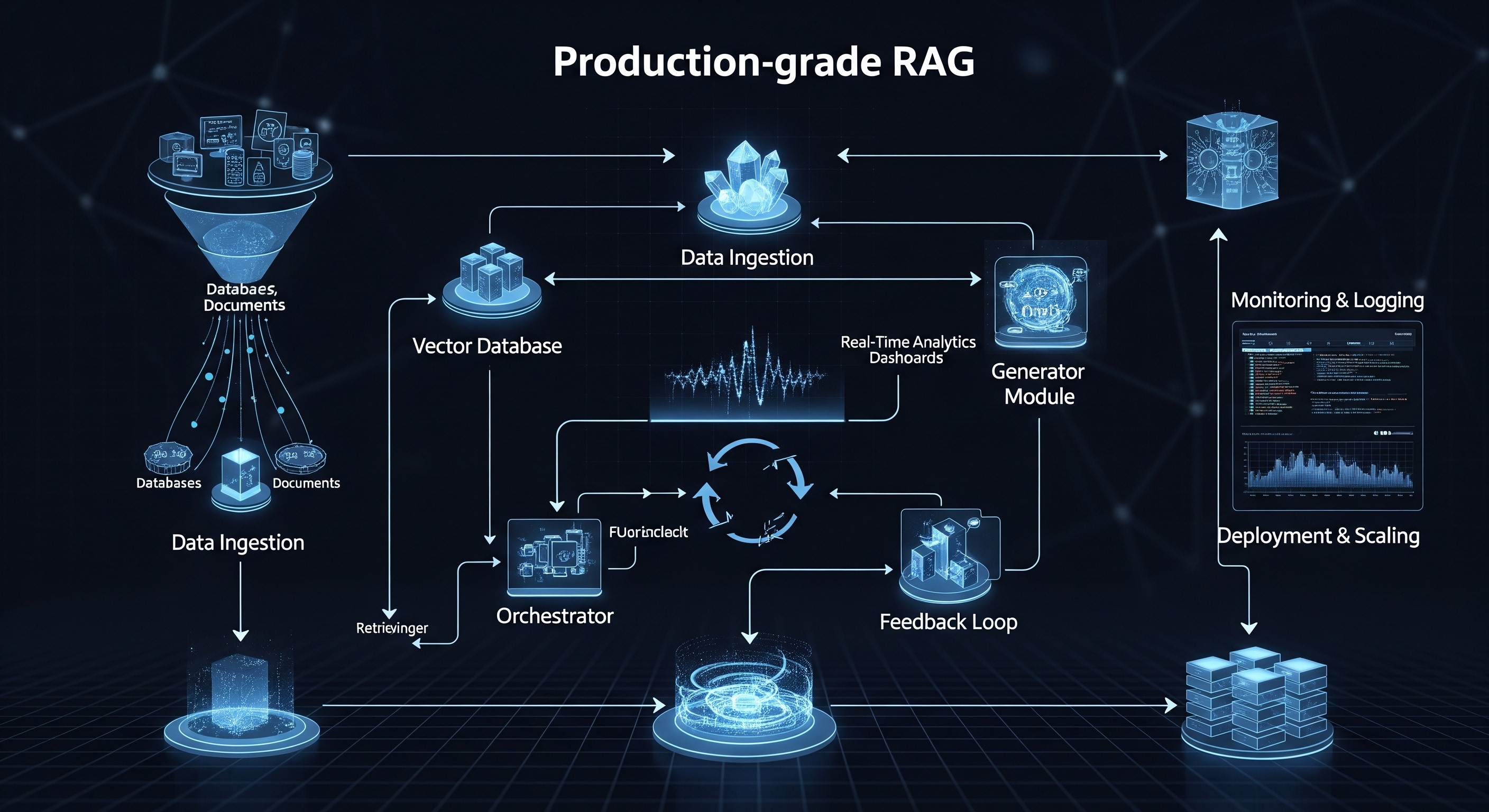
The Anatomy of a Production RAG Pipeline
A simple RAG prototype might involve a single script that loads a document, splits it, embeds it, and answers a query. A production system, however, is a complex, multi-stage architecture of interconnected services.
Here are the core components:
1. Data Ingestion & Processing Pipeline: Your data is the bedrock of your RAG system. In production, you can't just point to a single PDF file. You need a robust pipeline that can:
-
Connect to Diverse Sources: Pull data from APIs, databases, and document stores like Notion, Slack, Google Drive, or Confluence.
-
Process Various Formats: Reliably parse PDFs, DOCX, HTML, JSON, and more, extracting clean text.
-
Chunk Intelligently: Splitting documents into chunks is critical. Simple fixed-size chunking is often suboptimal. Production systems require sophisticated strategies like semantic chunking or agentic chunking to preserve context and meaning. This needs to be an automated, event-driven process (e.g., when a new document is added to a folder).
2. Embedding Generation: This is the process of converting your text chunks into numerical representations (vectors) using an embedding model.
-
Model Selection: Choosing the right model (e.g., OpenAI's
text-embedding-3-large, Cohere'sembed-v3.0, or open-source models) is a trade-off between performance, cost, and context length. -
Compute Resources: Embedding is a computationally intensive task. Processing millions of documents requires dedicated compute resources, often GPUs, managed through batch processing jobs and queuing systems to avoid bottlenecks.
3. Vector Storage & Indexing (The Vector Database): The generated embeddings are stored in a specialized vector database for efficient retrieval.
-
High-Speed Search: Your database must perform lightning-fast similarity searches across billions of vectors. This is achieved using indexing algorithms like HNSW (Hierarchical Navigable Small World).
-
Filtering & Metadata: A production system must support rich metadata filtering. For example, a user might need to search for information only within documents tagged "Q3-2025 Financials" and created by "User X".
-
Availability & Backups: The vector database is a mission-critical stateful component. It requires high availability, replication, and robust backup/restore procedures.
4. The Retrieval and Generation Service: This is the core application logic that handles user requests.
-
Advanced Retrieval: A simple k-NN (k-Nearest Neighbors) search is often not enough. Production systems employ hybrid search (combining keyword and semantic search) and re-ranking models to significantly improve the quality of the retrieved context before it's sent to the LLM.
-
Prompt Engineering: The final prompt sent to the LLM is a finely-tuned template that includes the user's query and the retrieved context. This requires rigorous versioning and testing.
-
LLM Interaction: The service calls the LLM (like GPT-4o or Claude 3.5 Sonnet), handles API errors, manages rate limits, and often streams the response back to the user for a better experience.
The Scalability Challenge: From One User to One Million
A system that works for one user will crumble under the load of a thousand concurrent users unless it's designed to scale.
-
Scaling Ingestion: Can your system handle a user uploading 10,000 documents at once? This requires decoupling the ingestion process using message queues (like RabbitMQ or Kafka) and scalable workers (like AWS Lambda or Kubernetes pods).
-
Scaling Retrieval: Vector databases are built for this, but as your index grows into the billions of vectors, you need to think about sharding (partitioning your index across multiple machines) and replication to maintain low latency.
-
Scaling Generation: The LLM generation step is often the slowest part of the process. You need to handle LLM API rate limits, load balance requests across multiple API keys or even different model providers, and implement intelligent caching strategies to avoid re-generating answers for common queries.
The Elephant in the Room: Skyrocketing Costs
While building your own RAG system offers maximum control, it comes with significant and often unpredictable costs.
1. Compute Costs:
-
Embedding: GPUs are expensive. Running a dedicated GPU cluster 24/7 for embedding jobs can cost thousands of dollars per month.
-
Application Hosting: The CPUs running your API, retrieval services, and workers add up.
2. LLM API Costs: This is the silent killer of many RAG project budgets. The cost is typically per-token, and it's a function of both the input context and the generated output.
With thousands of users and long, detailed documents, this cost can explode unexpectedly.
3. Vector Database Costs: Whether you pay for a managed SaaS vector database (which can be expensive at scale) or pay the operational overhead of hosting and managing an open-source one yourself, this is a significant line item.
4. Human Costs: Perhaps the most significant cost is the team of skilled (and expensive) engineers required to build, maintain, monitor, and troubleshoot this complex system. You don't just need an AI developer; you need DevOps engineers, data engineers, and backend specialists.
The Build vs. Buy Dilemma: A Smarter Path Forward
As we've seen, building a production-grade RAG system is a formidable engineering challenge, fraught with complexities in infrastructure, scalability, and cost management. It distracts you from what you actually want to do: build a fantastic user-facing product powered by AI.
This is where a managed platform like RAGlink comes in.
We handle the heavy lifting so you don't have to. Our platform provides a fully managed, auto-scaling infrastructure that's been battle-tested for performance and reliability.
-
Skip the Complexity: Connect your data sources in a few clicks. We handle the parsing, chunking, embedding, and indexing automatically.
-
Scale Effortlessly: Our serverless architecture scales transparently from one user to millions without you needing to manage a single server.
-
Control Your Costs: With optimized pipelines and predictable pricing, you can avoid surprise LLM bills and focus on building your application.
-
Focus on Your Product: Instead of spending months building and debugging infrastructure, you can deploy a powerful, production-ready RAG application in days.
Ready to skip the complexity and deploy a powerful RAG application today?
