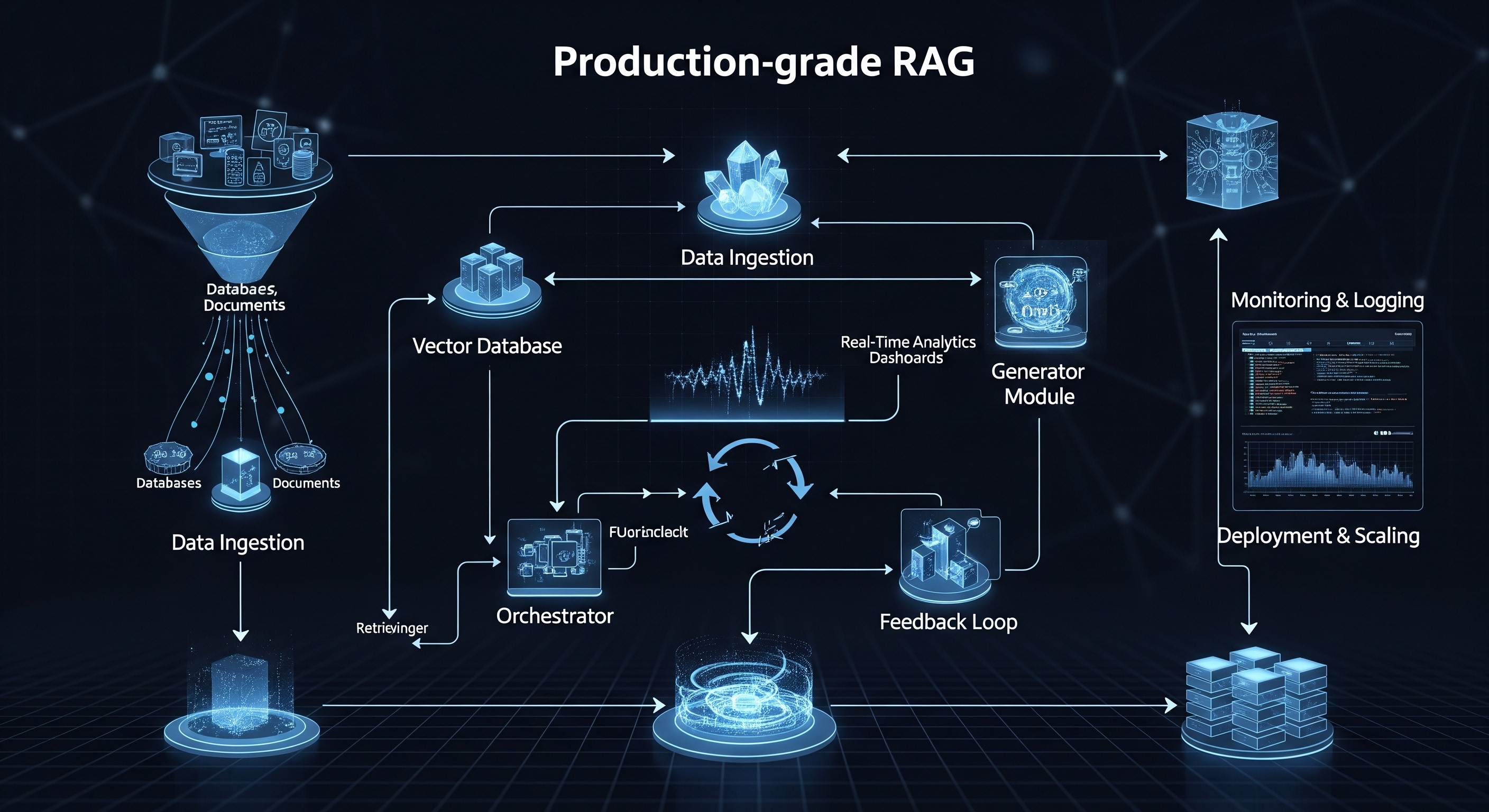
Plongée au cœur de notre pipeline RAGaaS axé sur la confidentialité
Dans le paysage en constante évolution de l'intelligence artificielle, la technologie RAG (Génération Augmentée par Récupération) s'est imposée comme une véritable révolution. En ancrant les Grands Modèles de Langage (LLM) dans vos données privées et propriétaires, la RAG permet d'atteindre des niveaux de précision et de pertinence sans précédent. Mais alors que nous nous empressons d'exploiter cette puissance, une question cruciale se pose : comment protégeons-nous les données mêmes qui renden…

CTO - Indie Hacker