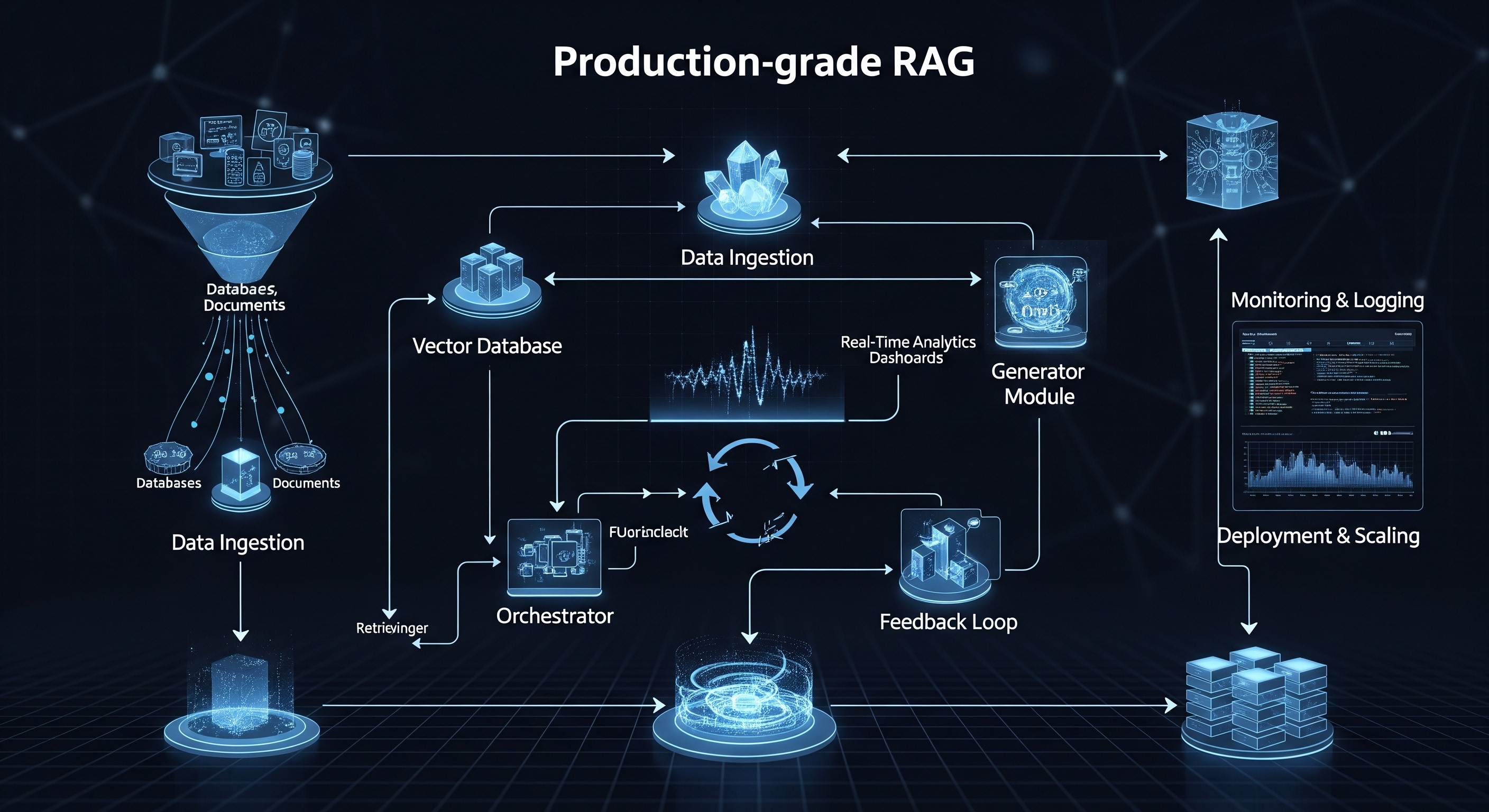
L'anatomie d'un pipeline RAG de production
Un prototype RAG simple peut consister en un unique script qui charge un document, le segmente, crée des embeddings et répond à une requête. Un système de production, en revanche, est une architecture complexe et multi-étapes de services interconnectés.
Voici les composants principaux :
1. Pipeline d'ingestion et de traitement des données : Vos données sont le fondement de votre système RAG. En production, vous ne pouvez pas simplement pointer vers un unique fichier PDF. Vous avez besoin d'un pipeline robuste capable de :
-
Se connecter à des sources diverses : Extraire des données d'API, de bases de données et de services de stockage de documents comme Notion, Slack, Google Drive ou Confluence.
-
Traiter divers formats : Analyser de manière fiable des PDF, DOCX, HTML, JSON, et plus encore, pour en extraire un texte propre.
-
Segmenter intelligemment : Diviser les documents en fragments ("chunks") est crucial. La simple segmentation par taille fixe est souvent sous-optimale. Les systèmes de production nécessitent des stratégies sophistiquées comme la segmentation sémantique pour préserver le contexte et le sens. Ce processus doit être automatisé et événementiel (par exemple, lorsqu'un nouveau document est ajouté à un dossier).
2. Génération des embeddings : C'est le processus de conversion de vos fragments de texte en représentations numériques (vecteurs) à l'aide d'un modèle d'embedding.
-
Sélection du modèle : Choisir le bon modèle (par exemple,
text-embedding-3-larged'OpenAI,embed-v3.0de Cohere, ou des modèles open-source) est un compromis entre performance, coût et longueur de contexte. -
Ressources de calcul : La création d'embeddings est une tâche gourmande en calcul. Traiter des millions de documents nécessite des ressources dédiées, souvent des GPU, gérées par des systèmes de traitement par lots et des files d'attente pour éviter les goulots d'étranglement.
3. Stockage et indexation des vecteurs (La base de données vectorielle) : Les embeddings générés sont stockés dans une base de données vectorielle spécialisée pour une récupération efficace.
-
Recherche à haute vitesse : Votre base de données doit effectuer des recherches de similarité ultra-rapides sur des milliards de vecteurs. Ceci est réalisé à l'aide d'algorithmes d'indexation comme HNSW (Hierarchical Navigable Small World).
-
Filtrage et métadonnées : Un système de production doit prendre en charge un filtrage riche par métadonnées. Par exemple, un utilisateur pourrait avoir besoin de rechercher des informations uniquement dans les documents étiquetés "Finances T3-2025" et créés par "Utilisateur X".
-
Disponibilité et sauvegardes : La base de données vectorielle est un composant avec état et critique. Elle nécessite une haute disponibilité, une réplication et des procédures de sauvegarde/restauration robustes.
4. Le service de récupération et de génération : C'est la logique applicative principale qui traite les requêtes des utilisateurs.
-
Récupération avancée : Une simple recherche k-NN (k-plus proches voisins) est souvent insuffisante. Les systèmes de production emploient une recherche hybride (combinant recherche par mots-clés et sémantique) et des modèles de reclassement (re-ranking) pour améliorer considérablement la qualité du contexte récupéré avant de l'envoyer au LLM.
-
Prompt Engineering : Le prompt final envoyé au LLM est un modèle finement ajusté qui inclut la requête de l'utilisateur et le contexte récupéré. Cela nécessite un versionnage et des tests rigoureux.
-
Interaction avec le LLM : Le service appelle le LLM (comme GPT-4o ou Claude 3.5 Sonnet), gère les erreurs d'API, les limites de taux d'appels (rate limits), et diffuse souvent la réponse en streaming à l'utilisateur pour une meilleure expérience.
Le défi de la scalabilité : passer d'un utilisateur à un million
Un système qui fonctionne pour un utilisateur s'effondrera sous la charge d'un millier d'utilisateurs simultanés s'il n'est pas conçu pour être scalable.
-
Scalabilité de l'ingestion : Votre système peut-il gérer un utilisateur téléchargeant 10 000 documents en une seule fois ? Cela nécessite de découpler le processus d'ingestion à l'aide de files d'attente de messages (comme RabbitMQ ou Kafka) et de workers scalables (comme AWS Lambda ou des pods Kubernetes).
-
Scalabilité de la récupération : Les bases de données vectorielles sont conçues pour cela, mais à mesure que votre index atteint des milliards de vecteurs, vous devez penser au sharding (partitionnement de votre index sur plusieurs machines) et à la réplication pour maintenir une faible latence.
-
Scalabilité de la génération : L'étape de génération par le LLM est souvent la partie la plus lente. Vous devez gérer les limites de taux des API LLM, répartir la charge des requêtes sur plusieurs clés d'API ou même différents fournisseurs de modèles, et mettre en œuvre des stratégies de mise en cache intelligentes pour éviter de régénérer des réponses pour des requêtes courantes.
L'énorme problème caché : l'explosion des coûts
Bien que construire votre propre système RAG offre un contrôle maximal, cela s'accompagne de coûts importants et souvent imprévisibles.
1. Coûts de calcul :
-
Embedding : Les GPU sont chers. Faire tourner un cluster de GPU dédié 24/7 pour les tâches d'embedding peut coûter des milliers de dollars par mois.
-
Hébergement de l'application : Les CPU qui exécutent votre API, vos services de récupération et vos workers s'additionnent.
2. Coûts des API LLM : C'est le tueur silencieux de nombreux budgets de projets RAG. Le coût est généralement par token, et il est fonction à la fois du contexte d'entrée et de la sortie générée.
Avec des milliers d'utilisateurs et des documents longs et détaillés, ce coût peut exploser de manière inattendue.
3. Coûts de la base de données vectorielle : Que vous payiez pour une base de données vectorielle SaaS gérée (qui peut être chère à grande échelle) ou que vous assumiez les frais opérationnels liés à l'hébergement et à la gestion d'une solution open-source, il s'agit d'un poste de dépense important.
4. Coûts humains : Le coût le plus important est peut-être l'équipe d'ingénieurs qualifiés (et coûteux) nécessaires pour construire, maintenir, surveiller et dépanner ce système complexe. Vous n'avez pas seulement besoin d'un développeur IA ; vous avez besoin d'ingénieurs DevOps, d'ingénieurs de données et de spécialistes backend.
Le dilemme "Construire ou Acheter" : une voie plus intelligente
Comme nous l'avons vu, construire un système RAG de qualité production est un formidable défi d'ingénierie, plein de complexités en matière d'infrastructure, de scalabilité et de gestion des coûts. Cela vous détourne de ce que vous voulez réellement faire : créer un produit fantastique pour vos utilisateurs, alimenté par l'IA.
C'est là qu'une plateforme gérée comme RAGlink entre en jeu.
Nous nous occupons des tâches lourdes pour que vous n'ayez pas à le faire. Notre plateforme fournit une infrastructure entièrement gérée et auto-scalable, éprouvée pour ses performances et sa fiabilité.
-
Évitez la complexité : Connectez vos sources de données en quelques clics. Nous gérons automatiquement l'analyse, la segmentation, l'embedding et l'indexation.
-
Évoluez sans effort : Notre architecture serverless s'adapte de manière transparente d'un utilisateur à des millions sans que vous ayez à gérer un seul serveur.
-
Contrôlez vos coûts : Avec des pipelines optimisés et une tarification prévisible, vous pouvez éviter les factures LLM surprises et vous concentrer sur la création de votre application.
-
Concentrez-vous sur votre produit : Au lieu de passer des mois à construire et à déboguer l'infrastructure, vous pouvez déployer une application RAG puissante et prête pour la production en quelques jours.
Prêt à laisser la complexité de côté et à déployer une application RAG puissante dès aujourd'hui ?
