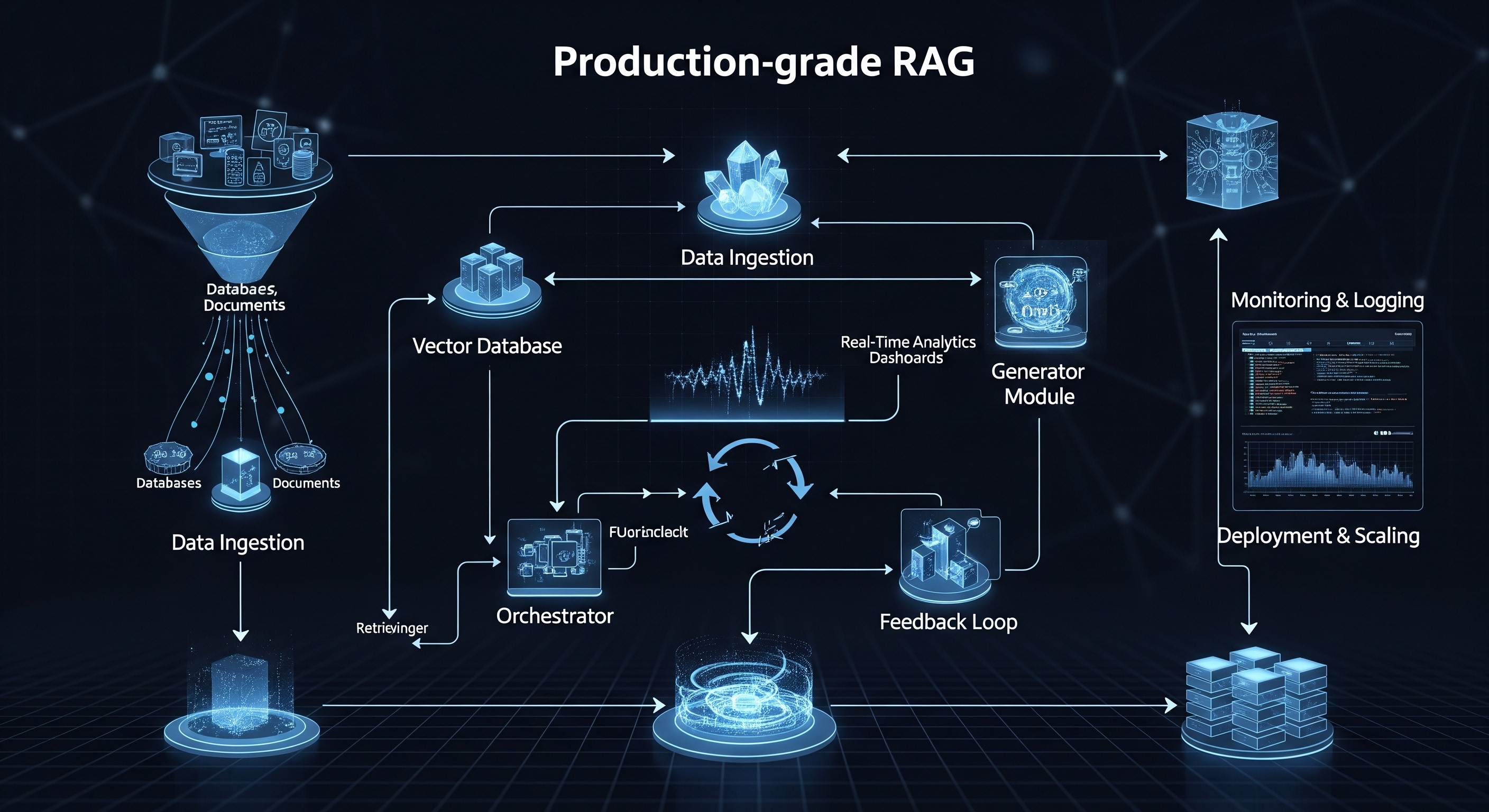
De Anatomie van een Productie-RAG-Pipeline
Een eenvoudig RAG-prototype kan bestaan uit een enkel script dat een document laadt, het opdeelt, er embeddings van maakt en een vraag beantwoordt. Een productiesysteem is daarentegen een complexe, meertrapsarchitectuur van onderling verbonden services.
Dit zijn de kerncomponenten:
1. Data-ingestie & Verwerkingspipeline: Uw data vormen het fundament van uw RAG-systeem. In productie kunt u niet zomaar naar één PDF-bestand verwijzen. U heeft een robuuste pipeline nodig die:
-
Verbindt met Diverse Bronnen: Data kan ophalen uit API's, databases en documentopslagsystemen zoals Notion, Slack, Google Drive of Confluence.
-
Verschillende Formaten Verwerkt: Betrouwbaar PDF's, DOCX, HTML, JSON en meer kan parsen om schone tekst te extraheren.
-
Intelligent Opdeelt (Chunking): Het opdelen van documenten in "chunks" is cruciaal. Eenvoudig opdelen in vaste groottes is vaak suboptimaal. Productiesystemen vereisen geavanceerde strategieën zoals semantisch opdelen om context en betekenis te behouden. Dit moet een geautomatiseerd, event-driven proces zijn (bijvoorbeeld wanneer een nieuw document aan een map wordt toegevoegd).
2. Genereren van Embeddings: Dit is het proces waarbij uw tekst-chunks worden omgezet in numerieke representaties (vectoren) met behulp van een embedding-model.
-
Modelselectie: Het kiezen van het juiste model (bijv. OpenAI's
text-embedding-3-large, Cohere'sembed-v3.0, of open-source modellen) is een afweging tussen prestaties, kosten en contextlengte. -
Computerbronnen: Het genereren van embeddings is een rekenintensieve taak. Het verwerken van miljoenen documenten vereist toegewijde computerresources, vaak GPU's, die worden beheerd via batchverwerkingsjobs en wachtrijen om knelpunten te voorkomen.
3. Vectoropslag & Indexering (De Vectordatabase): De gegenereerde embeddings worden opgeslagen in een gespecialiseerde vectordatabase voor efficiënte retrieval.
-
Hogesnelheidszoekopdrachten: Uw database moet bliksemsnel gelijkaardige vectoren kunnen vinden tussen miljarden vectoren. Dit wordt bereikt met indexeringsalgoritmen zoals HNSW (Hierarchical Navigable Small World).
-
Filtering & Metadata: Een productiesysteem moet uitgebreide filtering op metadata ondersteunen. Een gebruiker moet bijvoorbeeld kunnen zoeken naar informatie alleen binnen documenten met de tag "Financiën Q3-2025" en gemaakt door "Gebruiker X".
-
Beschikbaarheid & Back-ups: De vectordatabase is een bedrijfskritisch, stateful component. Het vereist hoge beschikbaarheid, replicatie en robuuste back-up- en herstelprocedures.
4. De Retrieval- en Generatielaag: Dit is de kernlogica van de applicatie die gebruikersverzoeken afhandelt.
-
Geavanceerde Retrieval: Een simpele k-NN (k-Nearest Neighbors) zoekopdracht is vaak niet voldoende. Productiesystemen gebruiken hybride zoekmethoden (een combinatie van trefwoord- en semantische zoekopdrachten) en re-ranking modellen om de kwaliteit van de opgehaalde context aanzienlijk te verbeteren voordat deze naar de LLM wordt gestuurd.
-
Prompt Engineering: De uiteindelijke prompt die naar de LLM wordt gestuurd, is een nauwkeurig afgestelde template die de vraag van de gebruiker en de opgehaalde context bevat. Dit vereist rigoureus versiebeheer en testen.
-
Interactie met de LLM: De service roept de LLM aan (zoals GPT-4o of Claude 3.5 Sonnet), handelt API-fouten af, beheert rate limits en streamt vaak het antwoord terug naar de gebruiker voor een betere ervaring.
De Uitdaging van Schaalbaarheid: Van Eén Gebruiker naar Eén Miljoen
Een systeem dat voor één gebruiker werkt, zal bezwijken onder de last van duizend gelijktijdige gebruikers, tenzij het is ontworpen om te schalen.
-
Schaalbaarheid van Ingestie: Kan uw systeem de upload van 10.000 documenten tegelijk aan? Dit vereist het ontkoppelen van het ingestieproces met behulp van berichtenwachtrijen (zoals RabbitMQ of Kafka) en schaalbare workers (zoals AWS Lambda of Kubernetes pods).
-
Schaalbaarheid van Retrieval: Vectordatabases zijn hiervoor gebouwd, maar naarmate uw index groeit tot miljarden vectoren, moet u nadenken over sharding (het verdelen van uw index over meerdere machines) en replicatie om een lage latentie te behouden.
-
Schaalbaarheid van Generatie: De LLM-generatiestap is vaak het traagste deel van het proces. U moet de rate limits van de LLM API beheren, verzoeken verdelen over meerdere API-sleutels of zelfs verschillende modelproviders, en intelligente cachingstrategieën implementeren om te voorkomen dat antwoorden op veelvoorkomende vragen opnieuw worden gegenereerd.
De Olifant in de Kamer: Torenhoge Kosten
Hoewel het bouwen van uw eigen RAG-systeem maximale controle biedt, brengt het aanzienlijke en vaak onvoorspelbare kosten met zich mee.
1. Computerkosten:
-
Embeddings: GPU's zijn duur. Een speciaal GPU-cluster 24/7 laten draaien voor embedding-taken kan duizenden euro's per maand kosten.
-
Applicatiehosting: De CPU's die uw API, retrieval-services en workers draaien, tellen op.
2. Kosten van de LLM API: Dit is de stille doder van veel RAG-projectbudgetten. De kosten zijn meestal per token en zijn een functie van zowel de invoercontext als de gegenereerde uitvoer.
Met duizenden gebruikers en lange, gedetailleerde documenten kunnen deze kosten onverwacht exploderen.
3. Kosten van de Vectordatabase: Of u nu betaalt voor een beheerde SaaS-vectordatabase (die op grote schaal duur kan zijn) of de operationele overhead betaalt voor het zelf hosten en beheren van een open-source variant, dit is een aanzienlijke kostenpost.
4. Personeelskosten: Misschien wel de belangrijkste kostenpost is het team van bekwame (en dure) ingenieurs dat nodig is om dit complexe systeem te bouwen, onderhouden, monitoren en problemen op te lossen. U heeft niet alleen een AI-ontwikkelaar nodig; u heeft DevOps-engineers, data-engineers en backend-specialisten nodig.
Het Dilemma "Zelf Bouwen of Kopen": Een Slimmere Weg Vooruit
Zoals we hebben gezien, is het bouwen van een productie-klaar RAG-systeem een formidabele technische uitdaging, vol complexiteit op het gebied van infrastructuur, schaalbaarheid en kostenbeheer. Het leidt u af van wat u eigenlijk wilt doen: een fantastisch, gebruikersgericht product bouwen dat wordt aangedreven door AI.
Dit is waar een beheerd platform als RAGlink in beeld komt.
Wij nemen het zware werk uit handen, zodat u dat niet hoeft te doen. Ons platform biedt een volledig beheerde, automatisch schaalbare infrastructuur die uitvoerig is getest op prestaties en betrouwbaarheid.
-
Sla de Complexiteit Over: Verbind uw databronnen met een paar klikken. Wij regelen automatisch het parsen, opdelen, embedden en indexeren.
-
Schaal Moeiteloos: Onze serverless architectuur schaalt transparant van één gebruiker naar miljoenen, zonder dat u ook maar één server hoeft te beheren.
-
Beheers uw Kosten: Met geoptimaliseerde pipelines en voorspelbare prijzen kunt u onverwachte LLM-rekeningen vermijden en u concentreren op het bouwen van uw applicatie.
-
Focus op uw Product: In plaats van maanden te besteden aan het bouwen en debuggen van infrastructuur, kunt u in enkele dagen een krachtige, productie-klare RAG-applicatie implementeren.
Klaar om de complexiteit over te slaan en vandaag nog een krachtige RAG-applicatie te implementeren?
